
Imagina un viernes 5:30 p. m.: las llamadas suben, el chat se congestiona y el canal de WhatsApp empieza a fallar. Aquí es donde la gestión de incidentes con ITIL separa el caos del control.
No se trata solo de “apagar incendios”, sino de restaurar el servicio con método, comunicar bien a los usuarios y aprender del tropiezo para no repetirlo.
Con ITIL, el Service Desk registra y categoriza, el Incident Manager orquesta y los equipos N1/N2 ejecutan sin peloteo. Mientras se activa un workaround, tu operación mantiene informados a los clientes (sin saturarlos) y el negocio sabe qué esperar gracias a SLAs claros.
La diferencia está en priorizar por impacto y urgencia, usar plantillas y auto-triage inteligente para ganar minutos clave, y cerrar con validación del usuario para evitar reabrir tickets.
Esta guía te baja a tierra el flujo completo, del primer reporte a la restauración, con métricas como MTTA/MTTR y prácticas de comunicación omnicanal que sostienen la confianza. Cero humo, cero burocracia: lo suficiente para empezar hoy, medir mañana y mejorar siempre.
¿Qué es un incidente en ITIL y por qué importa en CX B2B?
Un incidente en ITIL es cualquier interrupción o degradación del servicio que afecta a usuarios o clientes. No es una “solicitud de servicio” (algo nuevo que se pide) ni un “problema” (causa raíz).
Entender esta diferencia te ahorra tiempos muertos: clasificar bien desde el minuto cero acelera la restauración, mejora los SLAs y evita reabrir tickets.
Incidente vs. solicitud y problema
Cuando el bot de chat deja de responder o las respuestas en WhatsApp Business llegan con delay, estás ante un incidente porque el servicio habitual se rompió. Si, en cambio, un área pide una nueva cola de atención, es una solicitud.
Y si descubres que múltiples incidentes provienen de la misma falla de base de datos, eso es un problema a gestionar aparte. Esta distinción ordena el flujo, registrar, categorizar, priorizar y restaurar primero; investigar la causa raíz después, ya en problem management.
Ejemplos en Contact Center, e-commerce y fintech
En Contact Center, una caída de telefonía o un pico de errores en IVR impide atender. En e-commerce, un checkout intermitente dispara el “Where is my order?” y sube la presión en chat y correo.
En fintech, demoras en conciliaciones o fallas en autenticación bloquean transacciones.
Aquí la automatización de respuestas ayuda a contener el malestar: mensajes proactivos y FAQ automatizadas evitan duplicidad de tickets y mantienen informados a los usuarios mientras se aplica el workaround.
Riesgos de no gestionarlo bien (SLA rotos, fuga y costos)
Sin proceso ITIL, todo se vuelve “urgente”, los equipos se pisan y el cliente se entera tarde. Resultado: MTTR impredecible, backlog creciente, penalidades por SLA y, lo más caro, pérdida de confianza.
Con un esquema básico, Service Desk como puerta de entrada, Incident Manager como orquestador y N1/N2 con playbooks claros, reduces tiempos, subes la tasa de resolución al primer contacto y estabilizas la operación.
Clave para CX, ITIL no es burocracia; es foco en restaurar rápido y comunicar mejor. Si además conectas tu software de atención al cliente con plantillas y mensajes automáticos para clientes, alineas experiencia y eficiencia desde el primer minuto.
Roles y responsabilidades: Quién hace qué (sin fricción)
La gestión de incidentes con ITIL funciona solo si cada rol tiene claro su lugar y las transiciones son fluidas. En otras palabras, si el ownership está definido, el caos se reduce.
Un modelo operativo básico puede funcionar incluso con un equipo pequeño, siempre que haya orden en los flujos, comunicación clara y responsabilidad compartida.
Service Desk: Primera línea omnicanal
El Service Desk es el punto único de contacto (SPOC). Aquí se registran, categorizan y priorizan los incidentes que llegan por chat, correo, teléfono o WhatsApp. Su meta no es “cerrar tickets”, sino restaurar la operación del usuario lo antes posible.
Con herramientas omnicanal integradas, el Service Desk puede responder más rápido gracias a:
- Chatbots o bots de servicio al cliente que clasifican consultas recurrentes.
- Respuestas automáticas omnicanal para informar sobre el estado del incidente.
- Bases de conocimiento que guían al agente hacia soluciones rápidas.
Esta capa es crítica para mantener informado al cliente y al negocio, incluso cuando la solución final aún está en manos técnicas.
Y para que puedas conocer el concepto de una plataforma omnicanal, te recomiendo este vídeo donde también te enseño a cómo implementarlo. 🫡
Incident Manager: Coordinación y accountability
El Incident Manager es quien se asegura de que nada se pierda en el camino. Supervisa prioridades, escalaciones y tiempos de respuesta (MTTA y MTTR). Su responsabilidad es mantener la visión general y comunicar con claridad el estado del servicio a los stakeholders.
Un buen Incident Manager usa tableros en tiempo real y define los criterios de escalamiento. También promueve revisiones post-incidente sin buscar culpables, enfocándose en la causa y la mejora continua.
Escalamiento N1/N2/N3 y “swarming”
Los equipos N1 resuelven incidentes conocidos y documentados. Los N2 y N3 entran cuando el diagnóstico requiere habilidades especializadas o acceso a sistemas críticos.
En entornos ágiles, el modelo clásico de escalamiento puede reemplazarse por el swarming: todos los perfiles relevantes colaboran en tiempo real para resolver más rápido, sin pasar el ticket de mano en mano. Este modelo es ideal en BPO y Contact Centers con alta presión de SLA.
Una gestión de incidentes madura no se trata de jerarquías, sino de flujos de comunicación eficientes. Definir roles y herramientas desde el inicio evita que los agentes trabajen a ciegas y mantiene al cliente informado en todo momento, sin perder el toque humano.
Justo tengo un vídeo que explica el concepto de CX y como evitar cuellos de botella, te lo dejo aquí. 👇😃
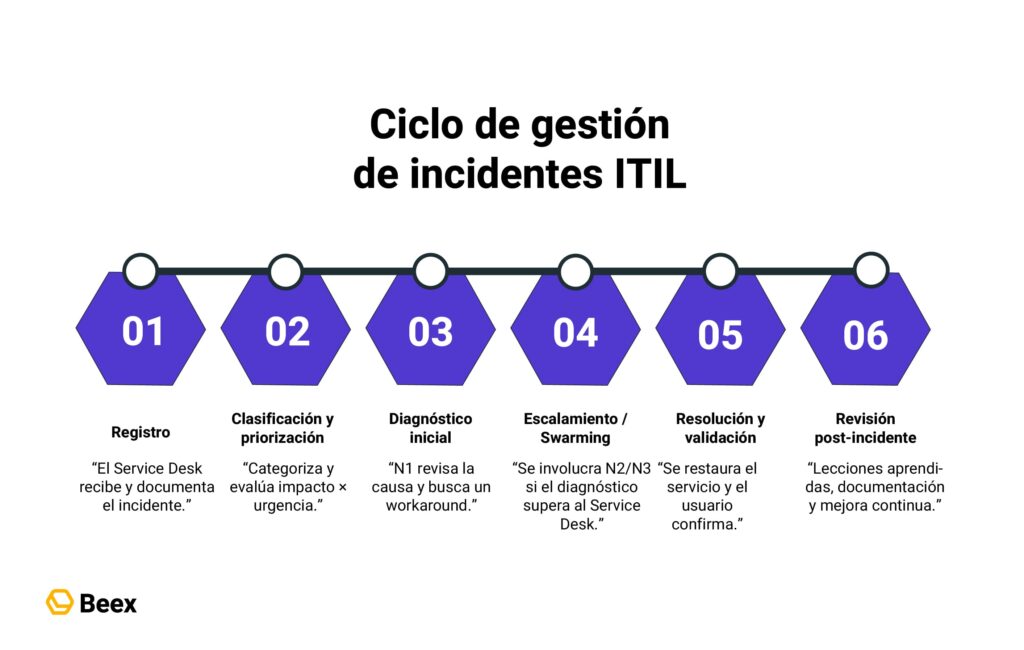
Flujo ITIL de punta a punta: Ticket y restauración
La magia de ITIL está en la estructura. No necesitas reinventar el proceso, basta con seguir un flujo disciplinado que transforme el caos en trazabilidad. Un incidente bien gestionado no solo se resuelve; deja aprendizaje y mejora continua.
El flujo base consta de ocho etapas que pueden adaptarse según madurez y herramientas de tu empresa, registro, categorización, priorización, diagnóstico, workaround, resolución, cierre y revisión post-incidente.
Registro y categorización: Evita el “cajón desastre”
Todo inicia con un registro preciso, canal, fecha, usuario afectado, descripción y servicio impactado. Si tu Service Desk usa un software de atención al cliente omnicanal, asegúrate de que los formularios sean simples, pero estandarizados.
Una mala categorización genera cascadas de errores: tickets mal asignados, SLAs incumplidos y reportes poco fiables. Usa IA o plantillas de clasificación para sugerir categorías según palabras clave o canal de origen (voz, chat, correo, WhatsApp).
Te doy un tip, crea una taxonomía de servicios con tres niveles (categoría, subcategoría y tipo de incidente). Es el mapa que permite medir y automatizar después.
Priorización: Impacto × urgencia
El error común es tratar todo como urgente. ITIL recomienda una matriz de impacto vs. urgencia:
- Alta urgencia y alto impacto → atención inmediata (p. ej. caída total de canales).
- Alta urgencia y bajo impacto → contención rápida, pero con workaround.
- Bajo impacto y baja urgencia → se gestiona en ventana programada.
Definir esto desde el registro mejora los SLAs y reduce la frustración interna y del cliente.
¿Te gusta lo que estás leyendo? 🤔
Suscríbete aquí abajo 👇 y recibe los mejores artículos de atención al cliente que redactan nuestros especialistas ✍️.
Diagnóstico y workaround: Contener antes de resolver
El objetivo del diagnóstico inicial no siempre es eliminar la causa raíz, sino restaurar el servicio lo más pronto posible. Aquí entran los workarounds o soluciones temporales.
Por ejemplo, si el canal de WhatsApp está intermitente, se puede redirigir tráfico a otro canal (chat web o SMS) mientras se corrige la integración.
Un buen equipo documenta cada workaround, porque en ITIL cada evento deja huella que nutre la base de conocimiento y agiliza futuras respuestas automáticas.
Cierre y validación con el usuario
Antes de cerrar, valida con el usuario o área afectada que el servicio realmente quedó operativo. Este paso evita la reapertura de tickets (uno de los KPIs más críticos).
Automatiza notificaciones post-resolución con mensajes automáticos personalizados, agradece la paciencia, confirma la restauración y ofrece un canal para feedback. Esto refuerza la experiencia del cliente digital y reduce retrabajos.
Revisión post-incidente: La mejora continua empieza aquí
Cada incidente debe dejar un post-mortem breve y accionable. Reúne a los involucrados, revisa qué funcionó, qué no y qué debe documentarse en el catálogo de soluciones o en la base de conocimiento.
Las organizaciones que lo hacen sistemáticamente reducen hasta 30 % sus tiempos de resolución en tres meses, porque evitan errores repetidos y fortalecen la cultura de aprendizaje.
Takeaway: Un flujo ITIL bien aplicado convierte cada crisis en oportunidad de mejora. Si integras automatización, IA y comunicación omnicanal, los incidentes dejan de ser una pesadilla operativa y se vuelven insumo para optimizar toda la operación.
Si te gustaría realizar un buen seguimiento de incidencias, aquí te traigo un artículo que resolverá todas tus dudas. 🫡
💥 Cómo automatizar el seguimiento de incidencias en centros de atención al cliente
Organiza los reportes en un sistema que asigne prioridades y distribuya tareas según el tipo de solicitud. Configura notificaciones automáticas para mantener informados a clientes y agentes sobre el estado de cada caso.

SLAs, OLAs y métricas que logran cambios
Prometer menos y cumplir siempre. Ese es el espíritu detrás de los SLAs (acuerdos con el negocio/cliente) y OLAs (acuerdos internos entre áreas). Bien definidos, orientan prioridades, hacen predecible la operación y evitan discusiones cuando la presión sube.
Cómo fijarlos sin prometer de más
Un SLA describe el nivel de servicio esperado (tiempos de respuesta y de restauración, ventanas de atención, canales de comunicación y criterios de prioridad). Un OLA aterriza esos mismos compromisos entre equipos (Service Desk, N2/N3, DevOps, proveedor telco), para que el SLA sea factible y no un deseo.
Para que funcionen en la vida real:
- Ancla en impacto × urgencia. No todos los incidentes merecen la misma velocidad.
- Define “hechos” verificables. ¿Qué cuenta como “servicio restaurado”? Escríbelo.
- Explica la comunicación. Quién informa, por qué canal, con qué frecuencia y tono.
- Evita números absolutos sin datos. Inicia con supuestos conservadores y ajústalos con tu histórico.
- Refleja la omnicanalidad. Considera picos en voz, chat y WhatsApp y su prioridad relativa.
KPIs esenciales
Medir por medir no sirve. Elige pocos indicadores que activen decisiones y automatizaciones en tu software de atención al cliente:
- MTTA (Mean Time to Acknowledge). Velocidad en dar acuse y contexto inicial.
- MTTR (Mean Time to Restore). Tiempo total hasta la restauración efectiva.
- % Cumplimiento de SLA. Por prioridad; semáforos y alertas tempranas.
- Tasa de resolución al primer contacto (FCR) en N1. Señal de buena base de conocimiento.
- Tasa de reapertura. Si sube, faltó validación o la solución fue frágil.
- Backlog vivo. Incidentes abiertos vs. capacidad disponible, por categoría.
- Cola y edad del ticket. ¿Qué está envejeciendo? Prioriza drenaje.
Complementa con métricas de flujo, como tiempo en cada etapa (registro, diagnóstico, workaround, cierre). Esa trazabilidad revela cuellos de botella para automatizar la atención al cliente donde duele.
Tablero mínimo viable y alertas tempranas
Un tablero claro evita microgestión y ayuda al Incident Manager a anticiparse:
- Vista por prioridad y canal (voz/chat/WhatsApp).
- Tendencia de MTTR por categoría de incidente.
- Alertas SLA cuando el ticket cruza umbrales intermedios (no esperes al vencimiento).
- Mensajes automáticos para clientes cuando cambia el estado (recibido/diagnóstico/workaround/resuelto).
- FAQ automatizadas para reducir ruido durante incidentes masivos (estado del servicio, pasos temporales, ETA si es viable comunicarlo).
Buenas prácticas para acuerdos realistas
- Co-diseña SLAs con el negocio. Si finanzas o ventas no compran los criterios de prioridad, el papel no sirve.
- Prueba y ajusta cada 90 días. Usa tu histórico; lo “agresivo” sin capacidad real rompe confianza.
- Integra OLAs con proveedores. Si tu telco no tiene tiempos compatibles, tu SLA es humo.
- Documenta el “Definition of Restored”. Evita cierres prematuros que disparan reaperturas.
Los SLAs y OLAs efectivos son contratos de claridad. Con métricas enfocadas y respuestas automáticas omnicanal, conviertes la presión diaria en previsibilidad y mejoras continuas.
Herramientas y automatización: El ticketing y omnicanalidad
La tecnología no “hace ITIL” por ti, pero habilita velocidad y consistencia. El stack mínimo: una plataforma ITSM/ticketing sólida, monitoreo de servicios y un hub omnicanal para comunicar sin fricción.
Sobre eso, construyes automatización: plantillas, auto-triage con IA y respuestas automáticas omnicanal que mantengan la calma del cliente mientras restauras.
Mesa de ayuda/ITSM: Qué evaluar al elegir software
Un buen ITSM te da trazabilidad sin burocracia. Busca:
- Catálogo y taxonomía configurables (categoría/subcategoría/tipo).
- SLA/OLA nativos con alertas intermedias y pauses justificadas.
- Automatización de flujo: reglas por prioridad, enrutamiento a N2/N3, swarming.
- Base de conocimiento integrada para FCR en N1 y FAQ automatizadas hacia el front.
- API/Integraciones con canales (voz, chat, email, WhatsApp) y monitoreo.
Es muy importante porque sin estas piezas, el proceso se “rompe” en lo invisible: datos sucios, reportes inútiles y tickets que envejecen.
Automatizaciones rápidas que bajan MTTR
Empieza por “wins” que no requieren meses de proyecto:
- Plantillas y macros para diagnóstico inicial, solicitud de evidencias y cierre validado.
- Auto-triage por IA: Sugiere categoría, prioridad y equipo según texto y canal.
- Workflows condicionales: Si P1 y canal afectado=WhatsApp, notifica a CX cada 15 min con estado; si P3, agrupa en reporte diario.
- Desencadenadores de status → mensajes automáticos para clientes en cada cambio (recibido/diagnóstico/workaround/resuelto).
- Encuesta breve post-cierre para detectar reaperturas potenciales.
Por qué importa, es simple, automatizar lo repetitivo libera tiempo experto para el diagnóstico real.
Omnicanalidad y notificaciones: Informar sin saturar
La comunicación es parte de la restauración. Diseña un sistema con cadencia y tono:
- Estado inicial (T0–T15): Acuse + alcance del impacto + canal de updates.
- Durante workaround: Instrucciones concretas y FAQ automatizadas con pasos temporales.
- Resolución: Confirmación + validación + puerta para feedback.
Micro-plantillas
- Acuse: “Hemos detectado una interrupción que afecta a [servicio]. Prioridad [P]. Próxima actualización en [X min]. Gracias por tu paciencia.”
- Workaround: “Mientras normalizamos [servicio], puedes usar [canal alterno]. Estimamos próxima actualización [hora].”
- Cierre: “Servicio [restaurado]. Si notas intermitencias, responde este mensaje para revisar de inmediato.”
Otro pro tip, centraliza el “estado del servicio” en una landing simple y enlázala desde bot, chat y correo para automatizar la atención al cliente en incidentes masivos.
Integraciones clave que sí rinden
- Monitoreo ↔ ITSM: alertas crean tickets con contexto (métrica, host, timestamp).
- CRM ↔ ITSM: identifica clientes críticos; personaliza prioridad y comunicación.
- Canales ↔ ITSM: sincroniza notas y cambios de estado en tiempo real.
- Knowledge ↔ Bot: publica artículos verificados como respuestas automáticas a preguntas frecuentes durante la contingencia.
Menos “herramientas”, más flujo automatizado. Define lo mínimo, conéctalo bien y documenta en la base de conocimiento. El resultado: menos ruido, más restauraciones rápidas y clientes informados sin spam.
Conoce cómo Kontigo redujo su tiempo de primera respuesta a <1 mincon Beex 🎯
Analucía Siguas, Gerente de Marketing y Producto de GMoney, te cuenta cómo nuestra plataforma los ayudó en cerrar el 98% de sus consultas en primer contacto.

Conclusión
La gestión de incidentes con ITIL no es un manual rígido; es una forma de pensar la operación: orden, comunicación clara y mejora continua. Cuando cada incidente sigue un flujo predecible —registro, priorización, diagnóstico, workaround, resolución y revisión— tu operación deja de depender de héroes y empieza a depender del proceso.
Con SLAs realistas, OLAs que alinean a los equipos y métricas que muestran dónde actuar, los incidentes dejan de ser incendios diarios y se convierten en oportunidades para afinar capacidades, automatizar pasos repetitivos y fortalecer la experiencia del cliente digital.
Y cuando sumas automatización, bots de servicio al cliente, respuestas automáticas y un ITSM integrado, logras dos cosas: restauraciones más rápidas y usuarios informados en todo momento.
La promesa de ITIL no es cero incidentes; es cero sorpresas. Y eso, para CX, vale oro.
Si quieres acelerar tu gestión de incidentes, reducir MTTR y automatizar tus flujos, agenda un diagnóstico técnico rápido. En 30 minutos identificamos tus tres principales cuellos de botella y mapeamos mejoras accionables para tu operación.