
Imagina el lunes postcampaña: WhatsApp explotó, el chat web no da abasto y el IVR deriva a cualquier lado. El equipo corre, pero el cliente repite su caso una y otra vez. Este escenario no es casualidad, es el resultado de problemas del servicio al cliente que se repiten por falta de datos en tiempo real, procesos manuales y decisiones sin contexto.
La buena noticia también se pueden resolver sin “heroísmos” diarios si combinas automatización, gobierno de la información y métricas que importan para la experiencia del cliente (CX).
En este playbook vamos al grano. Partimos del síntoma (respuestas lentas, mensajes inconsistentes, WISMO eterno, reclamos mal gestionados) y bajamos a la causa raíz (enrutamiento básico, bases desactualizadas, backoffice desconectado).
Cerramos cada bloque con una solución de servicio al cliente aplicable esta semana, como priorizar intenciones en canales críticos hasta activar autoservicio útil con handoff suave a agente.
Nada de teoría hueca, te damos principios, ejemplos y KPIs accionables para medir avance, como FCR, AHT, CSAT y costo por contacto.
El objetivo es simple: menos fricción, más claridad y resultados sostenibles. Si hoy apagas incendios, mañana diseñas un flujo predecible. Si hoy dependes del “me dijo el área”, mañana tendrás acuerdos interáreas con SLA visibles. Y si hoy tu reporte llega tarde, mañana operarás con paneles en vivo y decisiones informadas. Vamos paso a paso: enfoque, priorización y ejecución disciplinada.
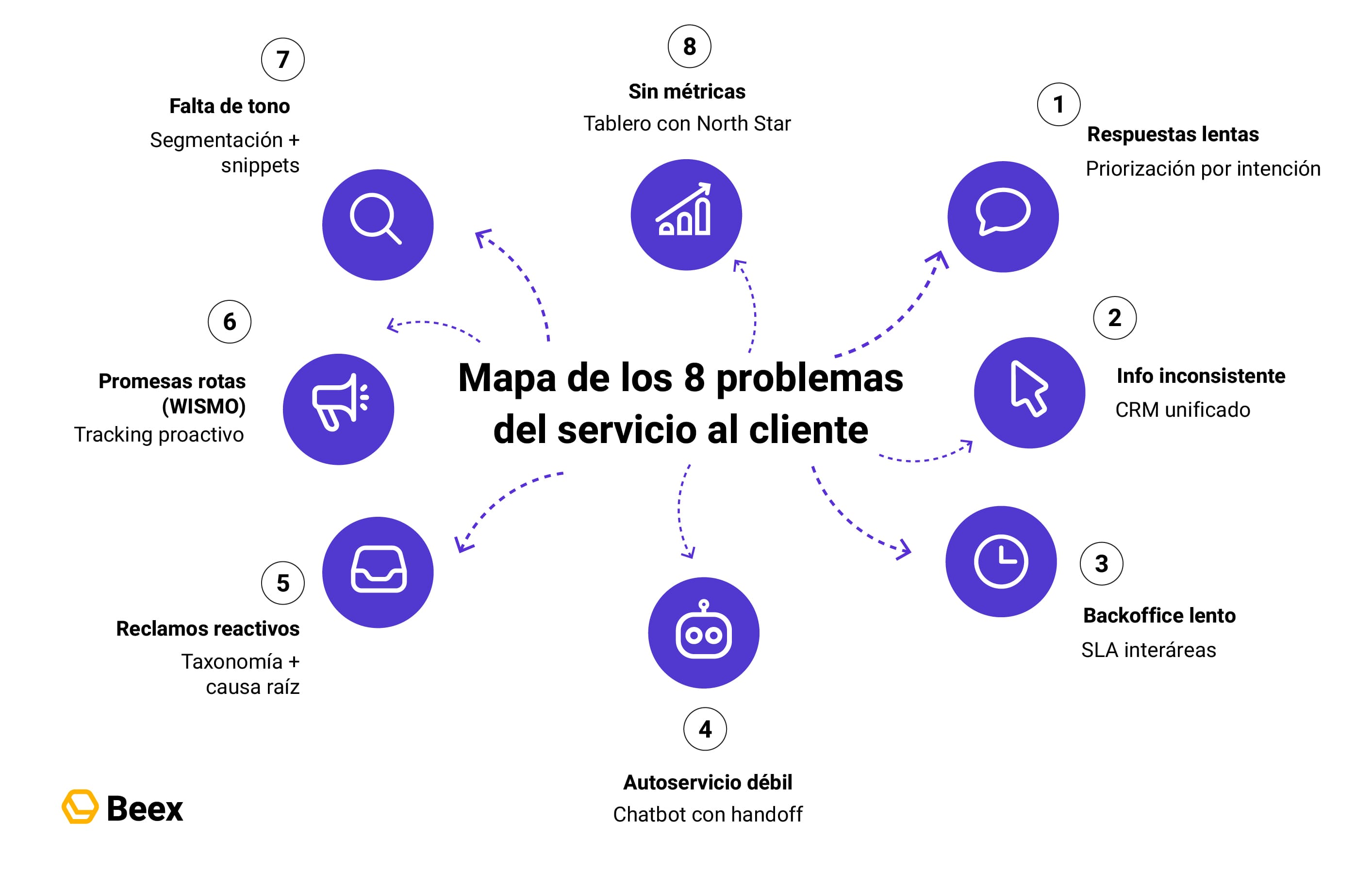
- 1) Problema 1: Respuestas lentas en canales críticos (WhatsApp, chat y voz)
- 2) Problema 2: Información inconsistente entre canales (el cliente repite su historia)
- 3) Problema 3: Backoffice lento y escalaciones eternas (el ticket “se pierde”)
- 4) Problema 4: Autoservicio que no sirve (FAQs que no resuelven y bots que frustran)
- 5) Problema 5: Gestión de reclamos reactiva (apagas incendios, no causas raíz)
- 6) Problema 6: Promesas logísticas rotas (WISMO eterno y entregas fuera de ventana)
- 7) Problema 7: Falta de personalización y tono
- 8) Causas raíz más típicas
- 9) Problema 8: Medición pobre y decisiones a ciegas (reportes tardíos que no explican nada)
- 10) Priorización y roadmap: Qué arreglo primero y cómo lo mido
- 11) Conclusión
Problema 1: Respuestas lentas en canales críticos (WhatsApp, chat y voz)
Cuando el volumen sube, la cola se estira y el cliente abandona. Es uno de los atención al cliente problemas comunes porque el enrutamiento suele ser “primero que entra, primero que atiende” y no por intención o valor.
Además, muchos equipos operan con múltiples bandejas y sin acuerdos de prioridad entre marketing, ventas y soporte.
Causas raíz más típicas
La demanda no se segmenta por motivo de contacto; los bots preguntan demasiado y resuelven poco; los agentes hacen “swivel chair” entre herramientas; y no existen SLA visibles ni protecciones para VIP/urgentes. Todo esto eleva AHT y derrumba la satisfacción del cliente.
Solución paso a paso (implementación en 2–4 semanas)
- Clasifica por intención y urgencia. Entrena un etiquetado simple (10–15 intents) y un semáforo de prioridad: crítico (pago/caída/seguridad), alto (entrega/activación), normal (consulta).
- Encola de forma unificada. Una sola cola omnicanal con reglas: críticos a escuadras senior; altos a agentes con skill específico; normales a bot + agente.
- Activa respuestas rápidas y macros. Plantillas cortas por intención para reducir variabilidad y tiempo de redacción; adjunta enlaces de autoservicio cuando aplique.
- Orquesta bot + handoff suave. Bot resuelve verificaciones y preguntas frecuentes; si detecta frustración o palabras de riesgo, deriva con contexto completo.
- Expón SLA en vivo. Muestra el tiempo objetivo por prioridad al agente y supervisión; alerta si se excede y ofrece redistribución automática.
- Cierra el loop con backoffice. Cuando el caso dependa de otra área, crea sub-tarea con SLA interáreas y notifica proactivamente al cliente para evitar recontactos.
KPIs y señales de avance
- FRT (tiempo a primera respuesta) por prioridad: meta inicial ≤2 min en críticos.
- AHT por intención: 10–20% de reducción con macros y handoff correcto.
- Cumplimiento de SLA y abandono de chat/cola.
- CSAT post-interacción y tasa de recontacto a 72 h.
Priorizar por intención y valor ordena la demanda, y el bot se enfoca en pre-trabajo útil, no en cuestionarios. Un solo panel evita el “multi-bandeja” y los SLA en vivo alinean decisiones en minutos. Es una vía directa de cómo mejorar el servicio al cliente sin crecer plantilla de inmediato.
Requiere revisión de guiones, 1 sprint para intents, y gobierno básico de plantillas. No depende de grandes integraciones para empezar; la optimización de skills y colas entrega impacto rápido.
Y para que puedas mejorar tus respuesta en atención al cliente, te recomiendo este vídeo donde te enseño a diferenciar un lead frío de uno caliente. 🫡
Problema 2: Información inconsistente entre canales (el cliente repite su historia)
Cuando WhatsApp promete una cosa, el email otra y en voz “no aparece” el historial, la experiencia del cliente (CX) se quiebra. Es uno de los errores en atención al cliente más costosos: aumenta recontactos, retrabajo y baja la confianza.
Causas raíz más típicas
Historial fragmentado sin omnicanal real; CRM desactualizado o con duplicados; base de conocimiento sin gobierno (versiones viejas conviven con nuevas); plantillas libres que cada agente “adapta” a su estilo; y ausencia de controles de identidad (no se valida quién es quién).
Solución paso a paso
- Vista única del cliente: Unifica el timeline por ID único (email/teléfono + regla de empate). Define campos canónicos y reglas de deduplicación.
- Gobierno de contenido: Crea una librería de respuestas aprobadas por tema/canal. Control de versiones, caducidad y owner responsable.
- Plantillas dinámicas: Usa variables (nombre, pedido, estado) y snippets por intención. Elimina “estilos personales” y homologa el tono.
- Sincronización automática: Cada interacción escribe al CRM con la misma taxonomía (intención, estado, próximo paso). Nada de notas sueltas.
- Verificación de identidad ligera: En WhatsApp y chat, aplica verificación proporcional al riesgo (token OTP o datos de bajo riesgo).
- Reglas de canal coherentes: Si cambias una promesa (p. ej., plazo de entrega), actualiza la librería y lanza alerta a todos los canales.
- Capacitación breve y recurrente: Microlearning de 15 minutos quincenal sobre cambios de contenido y excepciones.
KPIs y señales de avance
- FCR (resolución en primer contacto) por canal.
- Repetición de contacto a 7 días y variabilidad de respuesta entre agentes.
- CSAT por caso con cruce multicanal.
- Tiempo de actualización de contenido (cambio → producción en horas, no días).
La coherencia reduce fricción cognitiva del cliente y del agente. Con contenido gobernado y sincronización al CRM, pasas de “cada quien responde como puede” a buenas prácticas en atención al cliente replicables. La verificación proporcional evita frenos innecesarios y cuida seguridad.
No exige re-plataformar todo: empieza con una capa de taxonomía común y plantillas dinámicas. La vista única puede iniciar con reglas de dedupe básicas y mejorar con el tiempo. Impacto tangible desde la semana 2.
Es importante el uso de plantillas para tus clientes, por eso te recomiendo esta guía con 25 platillas. 😁👇
🤖 25 plantillas de chatbot para encuestas de satisfacción al cliente
Conoce qué encuestas puedes enviarles a tus usuarios para conocer qué piensan sobre tu marca, producto o servicio.

Problema 3: Backoffice lento y escalaciones eternas (el ticket “se pierde”)
Cuando un caso sale del front y toca a logística, cobranzas, TI o facturación, el tiempo se dilata y el cliente queda en silencio. Los resultados los notas en los recontactos, promesas incumplidas y desgaste del equipo.
Es un clásico en la gestión de reclamos de clientes: nadie “es dueño” del cierre y la comunicación con clientes se rompe.
Causas raíz más típicas
No hay acuerdos interáreas (SLA, responsables, horarios de cut-off), los tickets viajan por correo/Excel sin trazabilidad, faltan estados estandarizados (pendiente, en verificación, con proveedor, resuelto), y no existen alertas por envejecimiento.
Además, el front-of-house no ve el avance del backoffice y queda a ciegas ante el cliente.
Solución paso a paso (implementación en 3–5 semanas)
- Define ownership y SLA interáreas. Por tipo de caso (p. ej., “nota de crédito”, “ajuste logístico”), nombra un case owner en backoffice y un SLA claro (p. ej., 24–48 h).
- Estandariza la taxonomía de estados. Máximo 6–8 estados visibles para todos y disparadores automáticos entre sistemas.
- Workflow con handoffs auditables. Nada de correos sueltos: cada escalación crea una sub-tarea con tiempo objetivo, checklist mínimo y comentarios centralizados.
- Alertas por aging y riesgo. Si un caso supera el 80% del SLA, notifica a líder y ofrece fast track (prioridad o compensación preaprobada).
- Visibilidad para front y cliente. Panel único con estado actual, próximo paso y fecha estimada; habilita notificación proactiva al cliente cuando cambie el estado.
- Plantillas de actualización. Mensajes breves por hito (“recibimos tu solicitud”, “en validación con proveedor”, “resuelto”) para evitar el “¿novedades?”.
- Cierre con aprendizaje. Cada reclamo cerrado alimenta un pareto de causas para prevención (cambiar política, ajustar integración, mejorar inventario).
KPIs y señales de avance
- TTR (tiempo total de resolución) por tipo de caso y área responsable.
- Aging >48/72 h y % fuera de SLA.
- Recontactos durante la escalación y CSAT postcierre.
- Backlog health: Tickets abiertos por agente/área y tendencia semanal.
Pones estructura donde había favores y correos. Con ownership, estados estándar y alertas, el tiempo muerto baja y el cliente ve progreso. Son estrategias de servicio al cliente que combinan proceso y transparencia: menos incertidumbre, más confianza.
Puede arrancar con el sistema actual si soporta sub-tareas y estados; si no, usa una capa de orquestación ligera. Los SLA interáreas requieren acuerdos ejecutivos, pero el win llega rápido al cortar recontactos y escalaciones improductivas.
Si te gustaría ofrecer un buen servicio al cliente, aquí te traigo un vídeo que resolverá todas tus dudas. 🫡
Problema 4: Autoservicio que no sirve (FAQs que no resuelven y bots que frustran)
Cuando el bot pregunta mucho y resuelve poco, el cliente abandona o pide agente de inmediato. El “autoservicio” termina elevando costos y dañando la experiencia del cliente (CX).
Es uno de los desafíos del servicio al cliente más subestimados: se implementa rápido, sin gobierno ni datos de intención.
Causas raíz más típicas
FAQs traducidas de manuales internos (no del lenguaje del cliente), intents creados “a ojo” sin revisar motivos de contacto reales, contenidos sin dueño ni caducidad, y cero medición de contención útil vs. desvíos al canal caro (voz). Además, el handoff suele ser duro, el agente no recibe contexto y el cliente repite su historia.
Solución paso a paso (implementación en 3–6 semanas)
- Diseña desde el top-10 de motivos. Extrae 90 días de datos y arma un pareto de motivos. Con eso define 12–15 intents “core” (no 50).
- Escribe en lenguaje del cliente. Cada intent con guía de diálogo breve, validaciones mínimas y caminos de decisión simples. Evita jerga interna.
- Base de conocimiento viva. Artículos cortos, actualizados y con owner. Incluye fecha de revisión y snippet reutilizable para bot y humano.
- Handoff suave y con memoria. Si el cliente pide agente o el bot detecta frustración, deriva con el transcript, el intent y los datos ya verificados.
- Autenticación proporcional al riesgo. Para consultas de estado, valida datos de bajo riesgo; reserva OTP/2FA para cambios sensibles.
- Métricas de calidad, no solo volumen. Mide contención “válida” (resuelto sin recontacto 72 h), CSAT del flujo del bot y caídas por paso.
- Ciclo de mejora quincenal. Reentrena intents con nuevos ejemplos, depura artículos poco usados y prueba copys/A-B en prompts y botones.
KPIs y señales de avance
- Tasa de contención válida (objetivo inicial 25–40% según industria).
- Abandono en flujos clave y recontacto a 72 h.
- CSAT del bot vs. humano en el mismo intent.
- Desvíos evitados a voz y costo por contacto.
El autoservicio útil no es un “FAQ con UI”: parte del motivo real, habla claro y recuerda lo ya dado. Con handoff informado, el cliente no repite y el agente acelera. Así pasas de “bot decorativo” a servicio postventa efectivo con impacto medible.
No requiere IA avanzada para empezar. Con 12–15 intents bien escritos, una KB gobernada y métricas simples, verás mejoras en 2–3 semanas. La sofisticación (NLU/LLM, búsqueda semántica) se agrega sobre una base ya ordenada.
Justo tengo un vídeo que explica el secreto de buen autoservicio, te lo dejo aquí.👇 😃
Problema 5: Gestión de reclamos reactiva (apagas incendios, no causas raíz)
Cuando el reclamo entra, todo gira en torno a “cerrarlo rápido” sin entender por qué ocurrió. Se repiten compensaciones, sube el costo y la fidelización de clientes se erosiona.
Este patrón es crítico en gestión de reclamos de clientes, se atiende el síntoma, no la enfermedad, y el cliente vuelve a contactar.
Causas raíz más típicas
Taxonomía difusa (cada agente etiqueta distinto), falta de evidencia (pruebas, logs, fotos), decisiones discrecionales sin límites (compensaciones desalineadas), poca trazabilidad de proveedores y cero análisis de tendencias.
Además, comunicación tardía, el cliente pide estado porque nadie se lo dio antes.
Solución paso a paso (implementación en 4–6 semanas)
- Taxonomía estándar y cerrada. Define 8–12 categorías de reclamo y 25–35 subcausas máximas. Prohíbe “otros” salvo validación de supervisor.
- Checklist de admisibilidad. Al crear el caso, exige datos mínimos (ID, canal, evidencia). Sin checklist completo, no corre el reloj del SLA.
- Rutas y límites de compensación. Tabla de decisión por severidad/recurrencia con topes y excepciones preaprobadas; evita arbitrariedad.
- Escuadras especializadas. Reclamos de facturación, logística o fraude con owners claros y documentación de “lo que resuelve cada área”.
- Comunicación proactiva y clara. Hitos fijos como recepción, diagnóstico, acción correctiva, cierre. Mensajes breves y fechas realistas.
- Cierre con causa raíz. Cada reclamo cerrado exige causal + acción preventiva (proceso, sistema, proveedor). Nada de cerrar sin aprendizaje.
- Revisión quincenal de tendencias (Pareto). Identifica las 3 subcausas que generan 60–80% de reclamos y lanza sprints correctivos cross-funcionales.
- Tablero de severidad. Visualiza reclamos por impacto (financiero, reputacional, repetición) y prioriza mejoras de alto ROI.
¿Te gusta lo que estás leyendo? 🤔
Suscríbete aquí abajo 👇 y recibe los mejores artículos de atención al cliente que redactan nuestros especialistas. ✍️
KPIs y señales de avance
- % de reclamos recurrentes por subcausa a 30/60 días (debe bajar trimestre a trimestre).
- TAT de cierre por severidad y cumplimiento de SLA.
- CSAT post-reclamo y NPS de clientes con resolución efectiva.
- Costo por reclamo y ahorro por compensaciones evitadas.
- Tasa de recontacto post-cierre a 7 días.
Estandarizar categorías, pruebas y límites mata la improvisación. Al obligar causa raíz y prevención, el equipo deja de apagar incendios y empieza a reducir la llegada de casos. La comunicación con clientes en hitos evita ansiedad y escalaciones innecesarias, claridad primero, compensación después.
Todo puede iniciarse con las herramientas actuales: un formulario guiado, reglas simples de negocio y una rutina de revisión quincenal. Si integras proveedores en el flujo (logística, pasarelas), agrega acuerdos mínimos de datos y tiempos. Es una de las soluciones de servicio al cliente con mejor ROI a 8–12 semanas.
Problema 6: Promesas logísticas rotas (WISMO eterno y entregas fuera de ventana)
Cuando el cliente pregunta “¿Dónde está mi pedido?” más de una vez, ya perdiste confianza y margen. El WISMO es caro, dispara contactos en voz/WhatsApp, presiona al front y erosiona la experiencia del cliente (CX).
Suele deberse a integraciones débiles con ERP/OMS/última milla y a promesas hechas sin considerar inventario, capacidad y ventanas reales.
Causas raíz más típicas
Fechas estimadas “promedio” que ignoran picos o zonas, falta de eventos de tracking normalizados (despachado, en tránsito, en reparto, intento fallido, entregado), nula visibilidad de excepciones (clima, dirección incorrecta, rotura de stock), y notificaciones tardías o inexistentes.
Además, el servicio postventa vive desconectado de logística: nadie avisa proactivamente.
Solución paso a paso (implementación en 4–6 semanas)
- Normaliza el track & trace. Define 6–8 eventos estándar desde el ERP/OMS y el carrier. Crea una API/capa de integración que unifique estados y timestamps.
- Ventanas de entrega realistas. Cambia fecha fija por ventana (p. ej., 14:00–18:00) según zona y capacidad. Muestra la ventana en checkout, email y WhatsApp.
- Notificaciones proactivas. Envía mensajes en los eventos críticos (despacho, en reparto, excepción, reprogramación). Permite self-service para reagendar.
- Autocorrección de datos. Si dirección/contacto no validan, dispara verificación por chat/OTP antes del día de reparto. Evita el “intento fallido”.
- Panel de excepciones. Un tablero para CX con filtros por carrier/zona/ SLA a punto de caer. Prioriza callbacks a pedidos críticos o de alto valor.
- Política clara de fallas. Establece reglas de compensación/reembolso y reposición con proveedores; evita decisiones caso a caso.
- FAQ y bot específicos WISMO. Flujos cortos: estado en tiempo real, reagendar, cambiar punto de entrega, reportar paquetes incompletos o dañados.
- Cierre con confirmación. Tras la entrega, confirma recepción y habilita NPS/CSAT; registra incidencias posentrega para feedback a logística y packing.
KPIs y señales de avance
- WISMO por pedido (contactos “¿dónde está?” / pedidos totales) y recontacto a 72 h.
- OTIF (on time, in full) por zona/carrier y % de entregas dentro de ventana.
- Tasa de excepciones (dirección inválida, falta de stock, clima) y tiempo de resolución.
- CSAT postentrega y costo por contacto asociado a WISMO.
- Intentos de entrega promedio (objetivo: ≤1.2–1.3) y devoluciones por no entrega.
La transparencia reduce ansiedad y contactos innecesarios; las ventanas realistas ajustan expectativas; y la normalización de eventos permite que bot, agente y cliente vean lo mismo. Con un panel de excepciones y reglas claras, pasas de reaccionar a prevenir.
No necesitas reemplazar tu ERP, basta una capa de integración ligera y acuerdos mínimos con carriers para exponer eventos. Empezar por top zonas/carriers captura 60–80% del impacto. Es una estrategia de servicio al cliente que devuelve margen y tiempo al equipo en pocas semanas.
Y este vídeo es preciso para conocer y evaluar si necesitas la logística omnicanal, conoce estos 6 pasos para medir la eficiencia. 👇😁
Problema 7: Falta de personalización y tono
Cuando cada respuesta parece “de manual” o el tono cambia según el agente, la experiencia del cliente (CX) pierde conexión. Es un freno silencioso: sube el esfuerzo percibido, cae la satisfacción del cliente y se desperdician oportunidades de cross/upsell.
En B2B, donde los tickets suelen mezclar soporte y cuenta, la personalización es clave para fidelización de clientes.
Causas raíz más típicas
Guiones rígidos y “para todos”, cero segmentación por valor/etapa, CRM con datos incompletos, ausencias de preferencias de canal/horario, y una biblioteca de respuestas sin reglas de tono de marca. Además, miedo a “personalizar mal” por compliance, lo que termina en mensajes genéricos que no resuelven ni conectan.
Solución paso a paso (implementación en 3–5 semanas)
- Segmenta simple y accionable. Dos ejes: valor (RFM/LTV) y momento (nuevo, activo, en riesgo). Con eso define 4–6 segmentos operativos.
- Preferencias claras. Recoge y respeta canal/horario/idioma y nivel de detalle deseado; guarda consentimiento y finalidades (base legal).
- Librería de tono y variaciones. Para cada intención, ten 2–3 variantes: directa, empática y técnica. Mantén consistencia de marca y evita jerga interna.
- Snippets con contexto. Plantillas dinámicas que integren nombre, productos/servicios activos, SLA aplicable y próximo paso sugerido.
- Siguiente mejor acción (NBA). Si el caso lo permite, sugiere upgrade/servicio complementario contextual (“ya que integraste WhatsApp, activa seguimiento WISMO”).
- Guardas de compliance. Campos sensibles enmascarados, límites de oferta (no vender cruzado en reclamo severo), y aprobaciones automáticas por umbral.
- Entrenamiento breve y continuo. Microlearning quincenal con ejemplos de “mal/bien” y feedback entre pares; revisa 10 tickets por escuadra.
- A/B en mensajes clave. Prueba cierres de caso, pedidos de feedback, y recuperaciones de riesgo; ajusta por segmento y canal.
KPIs y señales de avance
- CSAT por segmento y canal; NPS en cuentas clave.
- Tasa de retención/expansión (renovaciones, upgrades) en casos con NBA contextual.
- Variabilidad de AHT entre agentes (debe bajar si el snippet guía).
- Tasa de queja por tono o “trato impersonal”.
- Opt-in/uso de canales preferidos y CTR de mensajes postcierre.
La personalización efectiva reduce fricción y acelera decisiones, el cliente recibe lo que necesita, en su canal y con un tono que entiende. Con guardas de compliance, evitas excesos y mantienes buenas prácticas en atención al cliente. El NBA convierte soporte en valor sin forzar la venta.
No requiere CDP complejo para arrancar. Con segmentos operativos, snippets con variables y una librería de tono, ya se percibe el cambio en 2–3 semanas. La sofisticación (modelos de propensión) llega después, sobre datos limpios y reglas claras.
Si aún no tienes claro qué atención fideliza mucho más, aquí te traigo un vídeo que resolverá todas tus dudas. 🫡
Problema 8: Medición pobre y decisiones a ciegas (reportes tardíos que no explican nada)
Si el tablero llega los lunes con datos del jueves y sin contexto, decides tarde y mal. Es el cuello de botella más común entre los problemas del servicio al cliente, métricas operativas sin vínculo a negocio, definiciones distintas por canal y cero alerting en tiempo real.
Este resultado da iniciativas que “suenan bien”, pero no mueven satisfacción del cliente ni costo por contacto.
Causas raíz más típicas
KPI vanity (volumen, contactos atendidos) sin calidad ni resultado; definiciones distintas de FCR/AHT por canal; extracción manual (Excel) que rompe consistencia; y ausencia de una “North Star” que conecte CX con ingresos, retención o ahorro.
Además, los equipos miran tableros diferentes, operaciones ve colas; marketing, conversiones; finanzas, costos. Falta una historia única.
Solución paso a paso
- Define la North Star. Elige 1 métrica que conecte experiencia + negocio (p. ej., “% de casos resueltos en primer contacto con CSAT ≥4 y costo objetivo”).
- Estandariza 5 métricas puente. FCR, AHT, CSAT, NPS y costo por contacto, con diccionario de datos único y cálculo igual en todos los canales.
- Crea la línea base. Congela 4 semanas de referencia por canal/intención; a partir de ahí, mide deltas (no números sueltos).
- Tablero en vivo con alerting. Actualiza cada 5–15 min lo operativo (colas, SLA) y diario lo estratégico (FCR, CSAT, costo). Alertas por umbral y tendencia.
- Atribución simple. Marca cambios (nuevos scripts, bot, SLA) como “experimentos” y mide su efecto vs. línea base por 2–4 semanas.
- Vista ejecutiva y vista operativa. Una página para dirección (tendencias, impacto, ahorro) y otra para supervisión (colas, desvíos, acciones). Misma verdad, distinto zoom.
- Revisión quincenal. Ceremonia de 30–45 min: lo que mejoró/empeoró, hipótesis, siguiente experimento. Documenta y cierra el loop.
KPIs y señales de avance
- Disponibilidad del tablero y latencia de datos.
- FCR, AHT, CSAT, NPS, costo por contacto con tendencia a 4/8/12 semanas.
- % de alertas atendidas dentro de SLA y tiempo a reacción.
- Impacto por experimento (Δ en FCR/CSAT/costo) vs. línea base.
- Recontacto a 72 h y variación entre canales (consistencia).
Por qué funciona
Lo que no se mide bien, no mejora. Con North Star y métricas puente estandarizadas, las áreas hablan el mismo idioma y ejecutan experimentos con atribución. El alerting en vivo cambia el juego: decisiones en minutos, no postmortems semanales.
Así aterrizas estrategias de servicio al cliente con evidencia.
Factibilidad
No necesitas un data lake para empezar. Unifica definiciones en un diccionario, conecta fuentes clave (telefonía/chat/WhatsApp/CRM) y arma un tablero ligero. La disciplina quincenal asegura foco y aprendizaje compuesto.
Priorización y roadmap: Qué arreglo primero y cómo lo mido
La tentación es “arreglar todo ya”. Mejor ordenarlo con un marco simple que conecte impacto en experiencia del cliente (CX), esfuerzo técnico y riesgo operativo. Priorizar evita dispersión y acelera resultados visibles, clave para la fidelización de clientes y la confianza interna.
Cómo priorizar en 60 minutos (workshop express)
Empieza con una matriz impacto/esfuerzo. En el eje de impacto, estima efecto en FCR, AHT, CSAT y costo por contacto; en el de esfuerzo, considera integraciones, cambios de proceso y entrenamiento. Lleva cada problema a un cuadrante.
Los quick wins (alto impacto/bajo esfuerzo) se ejecutan primero; los fundacionales (alto impacto/alto esfuerzo) se planifican con hitos y mitigations.
Roadmap trimestral (4–6 semanas de piloto + 6–8 de escalado)
- Mes 1 (Quick wins):
- Enrutamiento por intención/urgencia y macros (Problema 1).
- Librería gobernada y plantillas dinámicas (Problema 2).
- Tablero operativo con SLA y alertas básicas (Problema 8).
Meta: FRT ≤2 min en críticos, -10% AHT en 3 intents, CSAT +0.2 pts en chat.
- Mes 2 (Autoservicio útil + backoffice visible):
- Top-12 intents y handoff con contexto (Problema 4).
- SLA interáreas y estados estándar + alertas por aging (Problema 3).
Meta: 25–35% contención válida; -20% recontacto a 72 h; TTR -15%.
- Mes 3 (Logística y personalización):
- Track & trace normalizado y notificaciones proactivas (Problema 6).
- Segmentación operativa + snippets con tono por segmento (Problema 7).
Meta: -30% WISMO por pedido en zonas piloto; NPS +5 pts en cuentas clave.
Cómo medir sin sesgos
- Línea base congelada: 4 semanas previas, por canal e intención.
- Diccionario de datos único: Definiciones de FCR, AHT, CSAT, NPS y costo por contacto.
- Atribución simple: Etiqueta cada cambio como experimento y compara vs. control.
- Ritual quincenal: Una página ejecutiva (tendencias/ahorro) y una operativa (colas/desvíos/acciones). Misma verdad, distinto zoom.
Por qué este orden funciona
Los quick wins estabilizan operación y bajan ruido. Lo fundacional (backoffice, WISMO) ataca costos estructurales y promesas al cliente. La personalización convierte soporte en valor. Es la vía más directa de cómo mejorar el servicio al cliente sin sobredimensionar el equipo.
Conoce cómo IttsaBus mejoró en un 22% la satisfacción del cliente en la reprogramación de viajes 📋
Iris Pérez Medina, Coordinadora de Marketing y Servicio al Cliente, nos cuenta cómo Beex ayudó a optimizar el proceso de atención al cliente.

Conclusión
Si hoy tu operación depende de “héroes” que corren detrás de los reclamos, el camino hacia la mejora está claro, prioriza por intención y valor, ordena los flujos entre áreas, normaliza la trazabilidad logística y mide con una North Star que conecte CX y negocio.
No se trata de cambiar todo de golpe, sino de avanzar en ciclos cortos y medibles. Cada mejora, una plantilla gobernada, un SLA visible o un bot que entiende la intención, suma velocidad, confianza y consistencia.
Cuando el cliente no repite su historia y el agente tiene contexto, el servicio deja de ser reactivo y se vuelve una ventaja competitiva.
El siguiente paso es aterrizarlo, mapea tus ocho puntos críticos, prioriza tres quick wins y arranca un piloto de cuatro a seis semanas con KPIs visibles (FCR, AHT, CSAT y costo por contacto).
Con datos en tiempo real y flujos orquestados, la experiencia mejora y los equipos vuelven a enfocarse en crear valor, no en apagar incendios. Lleva este enfoque a tu operación y demuestra que un servicio al cliente predecible también puede ser rentable, escalable y humano.
¿Listo para llevar tu servicio al siguiente nivel? En Beex, te ayudamos a automatizar el seguimiento de tu servicio al cliente con soluciones omnicanal diseñadas para el entorno B2B más exigente. Conoce nuestras herramientas, agenda una demo personalizada y empieza a transformar la experiencia de tus clientes hoy.